Building a Full Text Search Engine in Javascript
Nov 18 2023 - 10 min read

Building a Full Text Search Engine in Javascript
Lets talk about a full text search here for a minute. People use this functionality constantly, without even thinking about it. Starting from banal google this and then to even more intricate uses, such as grep. A Full Text Search - is a method for searching text (keywords) in a collection of documents. Documents can range from websites, newspaper articles, even databases and local SSD/HDD. There are plethora of companies that rely on the usage of FTS as a key factor delivering their business value. After being interviewed by one of those companies, I have decided to study this topic a bit further.
By the end of this article we will implement a Full Text Search Engine in Javascript. By Javascript I mean Typescript, because it sucks less. ʕっ•ᴥ•ʔっ By the end we will be able to scan millions of documents with milliseconds.
You should not rely on this solution for your production needs. Firstly, its a only a playful research done by your humble abode. Secondly, if you are concerned with speed, opt for a more performant language such as C++, Rust or Go. Lastly, there are a variety of tools that will do the job: Elastic Search, Solr, Algolia are all great choices. All of them built on top of Apache Lucene. That being said, the best opportunity to learn something is to build it. Plus, you'll finally stumble upon how algorithms can be used in real life. (⌐⊙_⊙)
Introduction
Full-text search - is a more advanced way to search a database. It quickly finds all instances of a term (word) in a table without having to scan rows and without having to know which column a term is stored in. Sounds familiar? Say hello to SQL gods for me. This works by using text indexes. A text index stores positional information for all terms found in the columns you create the text index on.
Let's start with a direct approach, we have a documents DB that serves us some documents, we would like to find occurances of the word.
interface Quote { id: number; author: string; text: string; } function search(docs: Quote[], term: string): Quote[] { const result: Quote[] = []; for (const doc of docs) { if (doc.text.includes(term)) { result.push(doc); } } return result; } // Example usage: const documents: Quote[] = [ { id: 1, author: 'Haruki Murakami', text: "I collect records. And cats. I don't have any cats right now. But if I'm taking a walk and I see a cat, I'm happy." }, { id: 2, author: 'Haruki Murakami', text: "Confidence, as a teenager? Because I knew what I loved. I loved to read; I loved to listen to music; and I loved cats. Those three things. So, even though I was an only kid, I could be happy because I knew what I loved." }, ]; const searchTerm: string = "cats"; const searchResults: Quote[] = search(documents, searchTerm); console.log(searchResults);
This works greatly, but imagine having millions of records about cats. After all, we all love them. (=^・ェ・^=))ノ彡☆
That's where usage of text indexing comes into play. But before we do that, let's improve our data a for extra efficiency.
Lets take a look at our data.
[ { "id": 1, "author": "Haruki Murakami", "text": "I collect records. And cats. I don't have any cats right now. But if I'm taking a walk and I see a cat, I'm happy.", }, { "id": 2, "author": "Haruki Murakami", "text": "Confidence, as a teenager? Because I knew what I loved. I loved to read; I loved to listen to music; and I loved cats. Those three things. So, even though I was an only kid, I could be happy because I knew what I loved."}, { "id": 3, "author": "Haruki Murakami", "text": "Concentration is one of the happiest things in my life." } ]
Organising Data
1) Tokenise our data
Tokeniser tokenises our data, meaning that it breaks text into individual tokens, removes individual quotes, question marks, etc.
['I', 'collect', 'records', 'And', 'cats', 'I', 'don't', 'have', 'any', 'cats', 'right', 'now' ...]
For this we can use a simple regex, here is an example for english.
const splitRegex = { english: /[^a-z0-9_'-]+/gim, }
2) Lowercase all characters in an array. JS has built-in method .toLowerCase().
3) Remove all the unusual characters.
const diacritics = [ {'base':'A', 'letters':'\u0041\u24B6\uFF21\u00C0\u00C1\u00C2\u1EA6\u1EA4\u1EAA\u1EA8\u00C3\u0100\u0102\u1EB0\u1EAE\u1EB4\u1EB2\u0226\u01E0\u00C4\u01DE\u1EA2\u00C5\u01FA\u01CD\u0200\u0202\u1EA0\u1EAC\u1EB6\u1E00\u0104\u023A\u2C6F'}, {'base':'AA','letters':'\uA732'}, {'base':'AE','letters':'\u00C6\u01FC\u01E2'}, {'base':'AO','letters':'\uA734'}, {'base':'AU','letters':'\uA736'}, {'base':'AV','letters':'\uA738\uA73A'}, {'base':'AY','letters':'\uA73C'}, {'base':'B', 'letters':'\u0042\u24B7\uFF22\u1E02\u1E04\u1E06\u0243\u0182\u0181'}, {'base':'C', 'letters':'\u0043\u24B8\uFF23\u0106\u0108\u010A\u010C\u00C7\u1E08\u0187\u023B\uA73E'}, {'base':'D', 'letters':'\u0044\u24B9\uFF24\u1E0A\u010E\u1E0C\u1E10\u1E12\u1E0E\u0110\u018B\u018A\u0189\uA779\u00D0'}, {'base':'DZ','letters':'\u01F1\u01C4'}, {'base':'Dz','letters':'\u01F2\u01C5'}, {'base':'E', 'letters':'\u0045\u24BA\uFF25\u00C8\u00C9\u00CA\u1EC0\u1EBE\u1EC4\u1EC2\u1EBC\u0112\u1E14\u1E16\u0114\u0116\u00CB\u1EBA\u011A\u0204\u0206\u1EB8\u1EC6\u0228\u1E1C\u0118\u1E18\u1E1A\u0190\u018E'}, {'base':'F', 'letters':'\u0046\u24BB\uFF26\u1E1E\u0191\uA77B'}, {'base':'G', 'letters':'\u0047\u24BC\uFF27\u01F4\u011C\u1E20\u011E\u0120\u01E6\u0122\u01E4\u0193\uA7A0\uA77D\uA77E'}, {'base':'H', 'letters':'\u0048\u24BD\uFF28\u0124\u1E22\u1E26\u021E\u1E24\u1E28\u1E2A\u0126\u2C67\u2C75\uA78D'}, {'base':'I', 'letters':'\u0049\u24BE\uFF29\u00CC\u00CD\u00CE\u0128\u012A\u012C\u0130\u00CF\u1E2E\u1EC8\u01CF\u0208\u020A\u1ECA\u012E\u1E2C\u0197'}, {'base':'J', 'letters':'\u004A\u24BF\uFF2A\u0134\u0248'}, {'base':'K', 'letters':'\u004B\u24C0\uFF2B\u1E30\u01E8\u1E32\u0136\u1E34\u0198\u2C69\uA740\uA742\uA744\uA7A2'}, {'base':'L', 'letters':'\u004C\u24C1\uFF2C\u013F\u0139\u013D\u1E36\u1E38\u013B\u1E3C\u1E3A\u0141\u023D\u2C62\u2C60\uA748\uA746\uA780'}, {'base':'LJ','letters':'\u01C7'}, {'base':'Lj','letters':'\u01C8'}, {'base':'M', 'letters':'\u004D\u24C2\uFF2D\u1E3E\u1E40\u1E42\u2C6E\u019C'}, {'base':'N', 'letters':'\u004E\u24C3\uFF2E\u01F8\u0143\u00D1\u1E44\u0147\u1E46\u0145\u1E4A\u1E48\u0220\u019D\uA790\uA7A4'}, {'base':'NJ','letters':'\u01CA'}, {'base':'Nj','letters':'\u01CB'}, {'base':'O', 'letters':'\u004F\u24C4\uFF2F\u00D2\u00D3\u00D4\u1ED2\u1ED0\u1ED6\u1ED4\u00D5\u1E4C\u022C\u1E4E\u014C\u1E50\u1E52\u014E\u022E\u0230\u00D6\u022A\u1ECE\u0150\u01D1\u020C\u020E\u01A0\u1EDC\u1EDA\u1EE0\u1EDE\u1EE2\u1ECC\u1ED8\u01EA\u01EC\u00D8\u01FE\u0186\u019F\uA74A\uA74C'}, {'base':'OI','letters':'\u01A2'}, {'base':'OO','letters':'\uA74E'}, {'base':'OU','letters':'\u0222'}, {'base':'OE','letters':'\u008C\u0152'}, {'base':'oe','letters':'\u009C\u0153'}, {'base':'P', 'letters':'\u0050\u24C5\uFF30\u1E54\u1E56\u01A4\u2C63\uA750\uA752\uA754'}, {'base':'Q', 'letters':'\u0051\u24C6\uFF31\uA756\uA758\u024A'}, {'base':'R', 'letters':'\u0052\u24C7\uFF32\u0154\u1E58\u0158\u0210\u0212\u1E5A\u1E5C\u0156\u1E5E\u024C\u2C64\uA75A\uA7A6\uA782'}, {'base':'S', 'letters':'\u0053\u24C8\uFF33\u1E9E\u015A\u1E64\u015C\u1E60\u0160\u1E66\u1E62\u1E68\u0218\u015E\u2C7E\uA7A8\uA784'}, {'base':'T', 'letters':'\u0054\u24C9\uFF34\u1E6A\u0164\u1E6C\u021A\u0162\u1E70\u1E6E\u0166\u01AC\u01AE\u023E\uA786'}, {'base':'TZ','letters':'\uA728'}, {'base':'U', 'letters':'\u0055\u24CA\uFF35\u00D9\u00DA\u00DB\u0168\u1E78\u016A\u1E7A\u016C\u00DC\u01DB\u01D7\u01D5\u01D9\u1EE6\u016E\u0170\u01D3\u0214\u0216\u01AF\u1EEA\u1EE8\u1EEE\u1EEC\u1EF0\u1EE4\u1E72\u0172\u1E76\u1E74\u0244'}, {'base':'V', 'letters':'\u0056\u24CB\uFF36\u1E7C\u1E7E\u01B2\uA75E\u0245'}, {'base':'VY','letters':'\uA760'}, {'base':'W', 'letters':'\u0057\u24CC\uFF37\u1E80\u1E82\u0174\u1E86\u1E84\u1E88\u2C72'}, {'base':'X', 'letters':'\u0058\u24CD\uFF38\u1E8A\u1E8C'}, {'base':'Y', 'letters':'\u0059\u24CE\uFF39\u1EF2\u00DD\u0176\u1EF8\u0232\u1E8E\u0178\u1EF6\u1EF4\u01B3\u024E\u1EFE'}, {'base':'Z', 'letters':'\u005A\u24CF\uFF3A\u0179\u1E90\u017B\u017D\u1E92\u1E94\u01B5\u0224\u2C7F\u2C6B\uA762'}, {'base':'a', 'letters':'\u0061\u24D0\uFF41\u1E9A\u00E0\u00E1\u00E2\u1EA7\u1EA5\u1EAB\u1EA9\u00E3\u0101\u0103\u1EB1\u1EAF\u1EB5\u1EB3\u0227\u01E1\u00E4\u01DF\u1EA3\u00E5\u01FB\u01CE\u0201\u0203\u1EA1\u1EAD\u1EB7\u1E01\u0105\u2C65\u0250'}, {'base':'aa','letters':'\uA733'}, {'base':'ae','letters':'\u00E6\u01FD\u01E3'}, {'base':'ao','letters':'\uA735'}, {'base':'au','letters':'\uA737'}, {'base':'av','letters':'\uA739\uA73B'}, {'base':'ay','letters':'\uA73D'}, {'base':'b', 'letters':'\u0062\u24D1\uFF42\u1E03\u1E05\u1E07\u0180\u0183\u0253'}, {'base':'c', 'letters':'\u0063\u24D2\uFF43\u0107\u0109\u010B\u010D\u00E7\u1E09\u0188\u023C\uA73F\u2184'}, {'base':'d', 'letters':'\u0064\u24D3\uFF44\u1E0B\u010F\u1E0D\u1E11\u1E13\u1E0F\u0111\u018C\u0256\u0257\uA77A'}, {'base':'dz','letters':'\u01F3\u01C6'}, {'base':'e', 'letters':'\u0065\u24D4\uFF45\u00E8\u00E9\u00EA\u1EC1\u1EBF\u1EC5\u1EC3\u1EBD\u0113\u1E15\u1E17\u0115\u0117\u00EB\u1EBB\u011B\u0205\u0207\u1EB9\u1EC7\u0229\u1E1D\u0119\u1E19\u1E1B\u0247\u025B\u01DD'}, {'base':'f', 'letters':'\u0066\u24D5\uFF46\u1E1F\u0192\uA77C'}, {'base':'g', 'letters':'\u0067\u24D6\uFF47\u01F5\u011D\u1E21\u011F\u0121\u01E7\u0123\u01E5\u0260\uA7A1\u1D79\uA77F'}, {'base':'h', 'letters':'\u0068\u24D7\uFF48\u0125\u1E23\u1E27\u021F\u1E25\u1E29\u1E2B\u1E96\u0127\u2C68\u2C76\u0265'}, {'base':'hv','letters':'\u0195'}, {'base':'i', 'letters':'\u0069\u24D8\uFF49\u00EC\u00ED\u00EE\u0129\u012B\u012D\u00EF\u1E2F\u1EC9\u01D0\u0209\u020B\u1ECB\u012F\u1E2D\u0268\u0131'}, {'base':'j', 'letters':'\u006A\u24D9\uFF4A\u0135\u01F0\u0249'}, {'base':'k', 'letters':'\u006B\u24DA\uFF4B\u1E31\u01E9\u1E33\u0137\u1E35\u0199\u2C6A\uA741\uA743\uA745\uA7A3'}, {'base':'l', 'letters':'\u006C\u24DB\uFF4C\u0140\u013A\u013E\u1E37\u1E39\u013C\u1E3D\u1E3B\u017F\u0142\u019A\u026B\u2C61\uA749\uA781\uA747'}, {'base':'lj','letters':'\u01C9'}, {'base':'m', 'letters':'\u006D\u24DC\uFF4D\u1E3F\u1E41\u1E43\u0271\u026F'}, {'base':'n', 'letters':'\u006E\u24DD\uFF4E\u01F9\u0144\u00F1\u1E45\u0148\u1E47\u0146\u1E4B\u1E49\u019E\u0272\u0149\uA791\uA7A5'}, {'base':'nj','letters':'\u01CC'}, {'base':'o', 'letters':'\u006F\u24DE\uFF4F\u00F2\u00F3\u00F4\u1ED3\u1ED1\u1ED7\u1ED5\u00F5\u1E4D\u022D\u1E4F\u014D\u1E51\u1E53\u014F\u022F\u0231\u00F6\u022B\u1ECF\u0151\u01D2\u020D\u020F\u01A1\u1EDD\u1EDB\u1EE1\u1EDF\u1EE3\u1ECD\u1ED9\u01EB\u01ED\u00F8\u01FF\u0254\uA74B\uA74D\u0275'}, {'base':'oi','letters':'\u01A3'}, {'base':'ou','letters':'\u0223'}, {'base':'oo','letters':'\uA74F'}, {'base':'p','letters':'\u0070\u24DF\uFF50\u1E55\u1E57\u01A5\u1D7D\uA751\uA753\uA755'}, {'base':'q','letters':'\u0071\u24E0\uFF51\u024B\uA757\uA759'}, {'base':'r','letters':'\u0072\u24E1\uFF52\u0155\u1E59\u0159\u0211\u0213\u1E5B\u1E5D\u0157\u1E5F\u024D\u027D\uA75B\uA7A7\uA783'}, {'base':'s','letters':'\u0073\u24E2\uFF53\u00DF\u015B\u1E65\u015D\u1E61\u0161\u1E67\u1E63\u1E69\u0219\u015F\u023F\uA7A9\uA785\u1E9B'}, {'base':'t','letters':'\u0074\u24E3\uFF54\u1E6B\u1E97\u0165\u1E6D\u021B\u0163\u1E71\u1E6F\u0167\u01AD\u0288\u2C66\uA787'}, {'base':'tz','letters':'\uA729'}, {'base':'u','letters': '\u0075\u24E4\uFF55\u00F9\u00FA\u00FB\u0169\u1E79\u016B\u1E7B\u016D\u00FC\u01DC\u01D8\u01D6\u01DA\u1EE7\u016F\u0171\u01D4\u0215\u0217\u01B0\u1EEB\u1EE9\u1EEF\u1EED\u1EF1\u1EE5\u1E73\u0173\u1E77\u1E75\u0289'}, {'base':'v','letters':'\u0076\u24E5\uFF56\u1E7D\u1E7F\u028B\uA75F\u028C'}, {'base':'vy','letters':'\uA761'}, {'base':'w','letters':'\u0077\u24E6\uFF57\u1E81\u1E83\u0175\u1E87\u1E85\u1E98\u1E89\u2C73'}, {'base':'x','letters':'\u0078\u24E7\uFF58\u1E8B\u1E8D'}, {'base':'y','letters':'\u0079\u24E8\uFF59\u1EF3\u00FD\u0177\u1EF9\u0233\u1E8F\u00FF\u1EF7\u1E99\u1EF5\u01B4\u024F\u1EFF'}, {'base':'z','letters':'\u007A\u24E9\uFF5A\u017A\u1E91\u017C\u017E\u1E93\u1E95\u01B6\u0225\u0240\u2C6C\uA763'} ]; export function replaceDiacritics(str: string): string { for (const {base, letters} of diacritics) { str = str.replace(letters, base) } return str; }
For more information about diacritics
4) Remove string duplicates. See? Those interview questions about removal of string duplicates can actually come in handy ٩(^‿^)۶
function removeDuplicates(str) { const arr = str.split(splitRegex.english); const set = new Set(arr); const res = [...set].join(" "); return res; }
5) Remove stop-words or words that carry little useful info a, the, is, are etc.
6) Stemming removing unnessary parts of words (lucky -> luck), this part iq quite complex, I recommend looking at Snowball, makes for stemming rules, compiled to other languages
Note: If you want to detect the language being used.
Final Result:
[ { "id": 1, "quote": ['collect', 'record', 'cats', 'right', ...]` }, "..." ]
Implementing Inverted Index
Now that we have normalised and improved our data, it is time to create a data structure to store it efficiently. For those purposes we need to introduce an Inverted Index. Inverted index is is DS where key will be a token itself, and value will be an array containing reference to all the documents containing this word. Inverted index is similar to the index that you see at the end of any book. It maps the terms that appear in the documents to the documents.
interface Data { id: number; author: string; text: string; } interface InvertedIndex { [key: string]: number[]; } function analyse(text: string): string[] { // Implement your text analysis logic here. // -> Tokenise our data // -> Lowercase all tokens // -> Remove duplicates // -> Remove stop-words `words that carry little useful info` a, the, is, are etc // -> Stemming `removing unnessary parts of words` (lucky -> luck) // For brevity, this example just splits the text into words. return text.split(" "); } function addDocumentsToIndex( index: InvertedIndex, docs: Data[] ): InvertedIndex { // loop through docs for (const doc of docs) { // loop through tokens for (const token of analyse(doc.quote)) { const ids = index[token]; if (ids !== undefined && ids[ids.length - 1] === doc.id) { // Don't add the same ID twice. continue; } if (ids) { index[token] = [...ids, doc.id]; } else { index[token] = [doc.id]; } } } return index; } function main() { const data = [ { id: 1, author: 'Haruki Murakami', text: "I collect records. And cats. I don't have any cats right now. But if I'm taking a walk and I see a cat, I'm happy." }, { id: 2, author: 'Haruki Murakami', text: 'Confidence, as a teenager? Because I knew what I loved. I loved to read; I loved to listen to music; and I loved cats. Those three things. So, even though I was an only kid, I could be happy because I knew what I loved.' }, { id: 3, author: 'Haruki Murakami', text: 'Concentration is one of the happiest things in my life.' } ]; const idx: InvertedIndex = {}; const updatedIndex = addDocumentsToIndex(idx, data); console.log(updatedIndex); } main(); function search(index: InvertedIndex, text: string): number[][] { const r: number[][] = []; function analyze(text: string): string[] { // Implement your text analysis logic here. // For simplicity, this example just splits the text into words. return text.split(" "); } for (const token of analyze(text)) { if (token in index) { r.push(index[token]); } } return r; } // Example usage: const idx: Index = { cat: [1, 2], record: [2], // ** // }; const searchResults = search(idx, "cat"); console.log(searchResults);
There you have it! Thank you for reading this far :)
Bonus
Still wondering whats under the hood of Full Text Search Engines? Lucene-based engines optimise for space using a prefix-based search. Using a Prefix tree could be seen as a great optimisation approach, because many words are sharing a common prefix (overcook, overcharge, overrate).
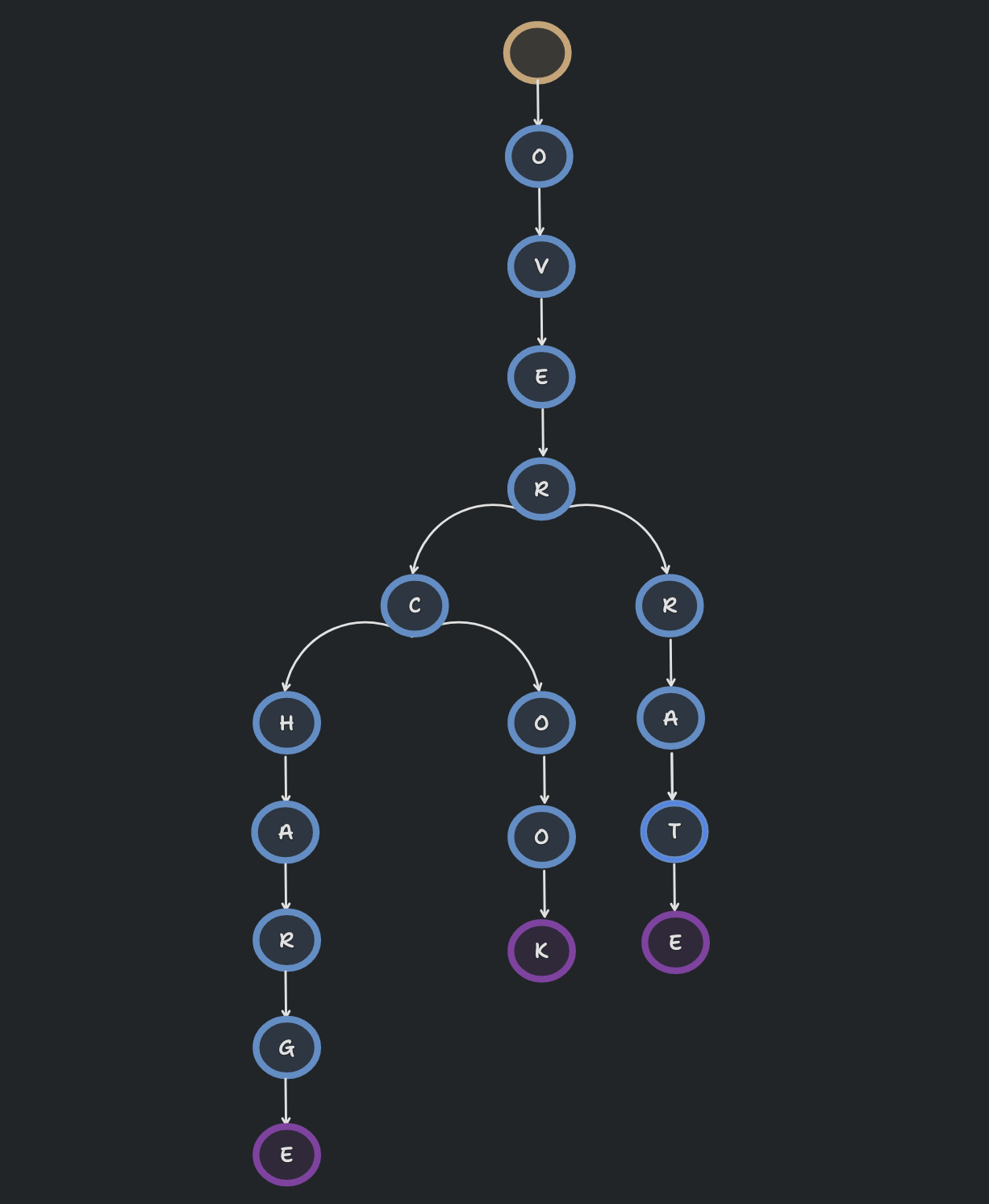
Lets implement the functionality for prefix tree:
//node.ts type Nullable<T> = T | null; export interface Node { id: string; key: string; word: string; parent: Nullable<string>; children: Record<string, string>; docs: string[]; end: boolean; } export function create(key= ""): Node { const node = { id: uniqueId(), key, word: "", parent: null, children: {}, docs: [], end: false, } Object.defineProperty(node, "toJSON", { value: serialize}); return node; } function serialize(this: Node): object { const {key, word, children, docs, end} = this return {key, word, children, docs, end}; } export function updateParent(node: Node, parent: Node): void { node.parent = parent.id node.word = parent.word + node.key } export function removeDocument(node: Node, docId: string): boolean { const index = node.docs.indexOf(docId); if (index === -1) { return false } node.docs.splice(index, 1); return true; }
//trie.ts export function insert(nodes: Nodes, node: Node, word: string, docId: string): void { const wordLength = word.length; for (let i = 0; i < wordLength; i++) { const char = word[i] if(!node.children?.[char]) { const newNode = createNode(char); updateParent(newNode, node); node = nodes[node.children[char]]; if (i === wordLength - 1) { node.end = true node.docs.push(docId) } } } } export type Nodes = Record<string, Node>; export type FindParams = { term: string; exact?: boolean; tolerance?: number; } export type FindResult = Record<string, string[]>; export function find(nodes: Nodes, node: Node, findParams: FindParams): FindResult { const { term, exact, tolerance } = findParams; const output: FindResult = {}; const termLength = term.length; for (let i = 0; i < termLength; i++) { const char = term[i]; const next = node.children?.[char] if (node.children?.[char]) { node = nodes[next] } else if (!tolerance) { return output } } findAllWorlds(nodes, node, output, term, exact, tolerance); return output }
What is tolerance? -> Dealing with misspeling wrld instead of world
Levenstein algorithm calculates the number of edit operations that are necessary to modify one string to obtain another string.
Use case examples of Levenstein algorithm: spell checkers, correction systems, search engines
export function levenshtein(a: string, b: string): number { if (!a.length) return b.length; if (!b.length) return a.length; let tmp; if (a.length > b.length) { tmp = a; a = b; b = temp; } const row = Array.from({ length: a.length + 1}, (_, i) => i); let val = 0; for (let i = 1; i <= b.length; i++) { let prev = i; for (let j = 1; j <= a.length; j++) { if (b[i - 1] === a[j - 1]) { val = row[j - 1]; } else { val = Math.min(row[j - 1] + 1, Math.min(prev + 1, row[j] + 1)); } row[j - 1] = prev; prev = val; } row[a.length] = prev; } return row[a.length] }
Further Reading
Tree Edit Distance (and Levenshtein Distance)
Simple fast algorithms for the editing distance between trees and related problems
What is the number one lesson you have learned from this article?
Recent publications
Found this article helpful? Try these as well ☺️